Taught by Patrick Hebron at ITP, Fall 2016
What is Learning?
Discussion:
We use the terms learning and intelligence often, but what do they mean?
- When a squirrel buries an acorn, does that require intelligence or mere instinct?
- What about when an ape uses a stick to extract ants from an anthill? Does that require intelligence?
- Is intelligence required for a calculator to perform a complex mathematical operation?
- What's the difference between rote operations, instinctual behaviors and learned behaviors?
- Does learning begin at birth or can it be inherited?
- When we say intelligence do we really mean human intelligence?
- Is it possible to provide universal definitions for the concepts of learning and intelligence?
Philosophical Framework
Experience as Data Visualization:

Would you call the above image a photograph?
In one sense, this image meets the standard criteria - its production began with the focusing of light upon a light-sensitive material.
Yet, the infrared light that produced this image is not visible to the human eye. In order for you to see it, the camera manufacturer had to map the information to a visible portion of the electromagnetic spectrum. In this case, a range of infrared intensity was mapped to a range of green intensity. The camera manufacturer could have chosen a different color as the mapping target. The choice may not be entirely arbitrary, but it is indeed a mapping, a translation of media.
In this sense, our experience of the above image has more in common with our experience of a weather map than with a conventional photograph.

This may lead us to the somewhat unsettling realization that:
Perhaps human vision itself is a kind of data visualization.
Our eyes send electrical signals that correspond to something real - the physical interaction of light with our surrounding environment.
But the way that we perceive these signals has a fundamental similarity to the sorts of data visualizations described above; they are mappings from one kind of information to another.
Q: Does the world really look like what we see?
A: It does to us.
Q: But what does the world really look like?
A: This question implies a perceiver. If the question were "what does it look like to no one?" then the answer should presumably be "nothing!" But, that does not mean that the world doesn't exist. It just means that the world exists in its own medium, which is not identical to the medium in which we perceive it.
The Nature of Experience Through a Kantian Lens:
- Rationalism vs. Empiricism
- Noumena and Phenomena
- Time, Space and Causality
Observing the Rules of Chess:
Categories of Machine Learning Algorithms
Excerpted from Machine Learning for Designers, published by O’Reilly Media, Inc., 2016.
In machine learning, the terms supervised, unsupervised, semi-supervised and reinforcement learning are used to describe some of the key differences in how various models and algorithms learn and what they learn about. There are many additional terms used within the field of machine learning to describe other important distinctions, but these four categories provide a basic vocabulary for discussing the main types of machine learning systems:
Supervised Learning:
These procedures are used in problems for which we can provide the system with example inputs as well as their corresponding outputs and want to induce an implicit approximation of the rules or function that governs these correlations. Procedures of this kind are “supervised” in the sense that we explicitly indicate what correlations should be found and only ask the machine how to substantiate these correlations. After it is trained, a supervised learning system should be able to predict the correct output for an input example that is similar in nature to the training examples, but not explicitly contained within it.
The kinds of problems that can be addressed by supervised learning procedures are generally divided into two categories: classification and regression problems. In a classification problem, the outputs relate to a set of discrete categories. For example, we might have an image of a handwritten character and want to determine which of 26 possible letters it represents. In a regression problem, the outputs relate to a real-valued number. For example, based on a set of financial metrics and past performance data, we might try to guess the future price of a particular stock.
Unsupervised Learning:
These procedures do not require a set of known outputs. Instead, the machine is tasked with finding internal patterns within the training examples. Procedures of this kind are “unsupervised” in the sense that we do not explicitly indicate what the system should learn about. Instead, we provide a set of training examples that we believe contains internal patterns and leave it to the system to discover those patterns on its own. In general, unsupervised learning can provide assistance in our efforts to understand extremely complex systems whose internal patterns might be too complex for humans to discover on their own. We also can use unsupervised learning to produce generative models, which can, for example, learn the stylistic patterns in a particular composer’s work and then generate new compositions in that style.
Unsupervised learning has been a subject of increasing excitement and plays a key role in the Deep Learning renaissance. One of the main causes of this excitement has been the realization that unsupervised learning can be used to dramatically improve the quality of supervised learning processes.
Semi-supervised Learning:
These procedures use the automatic feature discovery capabilities of unsupervised learning systems to improve the quality of predictions in a supervised learning problem. Instead of trying to correlate raw input data with the known outputs, the raw inputs are first interpreted by an unsupervised system. The unsupervised system tries to discover internal patterns within the raw input data, removing some of the noise and helping to bring forward the most important or indicative features of the data. These distilled versions of the data are then handed over to a supervised learning model, which correlates the distilled inputs with their corresponding outputs in order to produce a predictive model whose accuracy is generally far greater than that of a purely supervised learning system.
This approach can be particularly useful for cases in which only a small portion of the available training examples have been associated with a known output. One such example is the task of correlating photographic images with the names of the objects they depict. An immense number of photographic images can be found on the web, but only a small percentage of them come with reliable linguistic associations. Semi-supervised learning lets the system discover internal patterns within the full set of images and associate these patterns with the descriptive labels that were provided for a limited number of examples. This approach bears some resemblance to our own learning process in the sense that we have many experiences interacting with a particular kind of object, but a much smaller number of experiences in which another person explicitly tells us the name of that object.
Reinforcement Learning:
These procedures use rewards and punishments to shape the behavior of a system with respect to one or several specific goals. Unlike supervised and unsupervised learning systems, reinforcement learning systems are not generally trained on an existent dataset; instead, they learn primarily from the feedback they gather through performing actions and observing the consequences. In systems of this kind, the machine is tasked with discovering behaviors that result in the greatest reward, an approach which is particularly applicable to robotics and tasks like learning to play a board game in which it is possible to explicitly define the characteristics of a successful action but not how and when to perform those actions in all possible scenarios.
Machine Memorization vs. Machine Learning
Learning by Example:
Excerpted from Machine Learning for Designers, published by O’Reilly Media, Inc., 2016.
In logic, there are two main approaches to reasoning about how a set of specific observations and a set of general rules relate to one another.
In deductive reasoning, we start with a broad theory about the rules governing a system, distill this theory into more specific hypotheses, gather specific observations and test them against our hypotheses in order to confirm whether the original theory was correct.
In inductive reasoning, we start with a group of specific observations, look for patterns in those observations, formulate tentative hypotheses, and ultimately try to produce a general theory that encompasses our original observations.
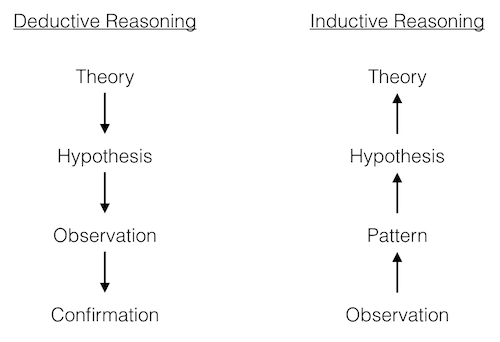
Each of these approaches plays an important role in scientific inquiry. In some cases, we have a general sense of the principles that govern a system, but need to confirm that our beliefs hold true across many specific instances. In other cases, we have made a set of observations and wish to develop a general theory that explains them.
To a large extent, machine learning systems can be seen as tools that assist or automate inductive reasoning processes.
Performing Rote Tasks:
Being able to produce the correct output for a given input is not necessarily a sign of learning or intelligence. It is important to consider how the output was achieved. It is not always easy to tell the difference between a rote operation and an intelligent one.
The items shown below can be described by concrete, general-purpose formulae and therefore can be performed by a machine without any learning.
It is also possible for a machine to learn these operations. But, when a concrete formula exists, it is almost always more efficient to use it over a learned approach. Learning is computationally intensive and should therefore be reserved for tasks that are not easily described by a concrete formula.
Arithmetic Operators:
- 2 + 2 = 4
- 3 * 4 = 12
Logical Truth Tables:
| P | Q | P and Q | P or Q | P exclusive-or Q |
|---|---|---|---|---|
| T | T | T | T | F |
| T | F | F | T | T |
| F | T | F | T | T |
| F | F | F | F | F |
Lookup Tables:
| X | sqrt( X ) |
|---|---|
| 1 | 1 |
| 2 | 1.414 |
| 3 | 1.732 |
| 4 | 2 |
Encoding Schemes:
Getting Started in Python
Hello, World:
print "Hello, World!"Variables:
myInt = 2
myReal = 3.14
myString = "hello"
print myInt
print myReal
print myStringArithmetic Operators:
print ( 1 + 2 )
print ( 3 - 1 )
print ( 2 * 3.14 )
print ( 8 / 3 )
print ( 8 / 3.0 )String Operators:
myString = "hello"
print( len( myString ) ) # prints string length
print( myString[0] ) # prints "h"
print( myString[0:2] ) # prints "he"
myString = myString.upper() # converts string to uppercase
myString = myString.lower() # converts string to lowercase
if "hello" == "hello":
print( "'hello' is equal to 'hello'" )
if "hello" in "hello world":
print( "'hello world' contains 'hello'" )Lists:
myList = [ "alfa", "bravo", "charlie", "delta", "echo" ]
print myList # prints all elements
print myList[ 0 ] # prints first element
print myList[ 1 ] # prints second element
myList.append( "foxtrot" ) # adds element
myList.remove( "charlie" ) # removes element
myList.sort() # sorts the list in alphabetical order
myList.reverse() # reverses orderLoops:
for i in range( 1, 10 ):
print i
myList = [ "alfa", "bravo", "charlie", "delta", "echo" ]
for item in myList:
print itemConditionals:
x = 7
if x < 10:
print 'x is less than 10'
else:
print 'x is greater than or equal to 10'
if x > 10 and x < 20:
print "x is in range"
else:
print "x is out of range"Functions:
def myFunc(x):
return x*x
print myFunc( 3 )Homework
Assignment:
- Implement Run-length encoding in Python. A decoder implementation is optional, but give it a shot.
Readings:
- The Nature of Code by Daniel Shiffman, Chapter 1: "Vectors" and Chapter 6.7: "The Dot Product"
- Computational Neuroscience and Cognitive Modelling, Chapter 9: "Neural Network Mathematics: Vectors and Matrices"
- Primary Source: Intelligent Machinery by Alan Turing
Optional:
- The History of Machine Learning from the Inside Out: A discussion with Geoffrey Hinton, Yoshua Bengio and Yann LeCun
- Building Smarter Machines: New York Times interactive on the history of machine learning